
Introducción
Cuando una persona abre Facebook, no ve todas las publicaciones disponibles en orden cronológico puro. Tampoco ve simplemente los posts con más likes. Lo que aparece en el Feed pasa por un sistema de ranking, es decir, un sistema que analiza publicaciones candidatas calcula probabilidades, asigna puntuaciones y decide qué contenido mostrar primero.
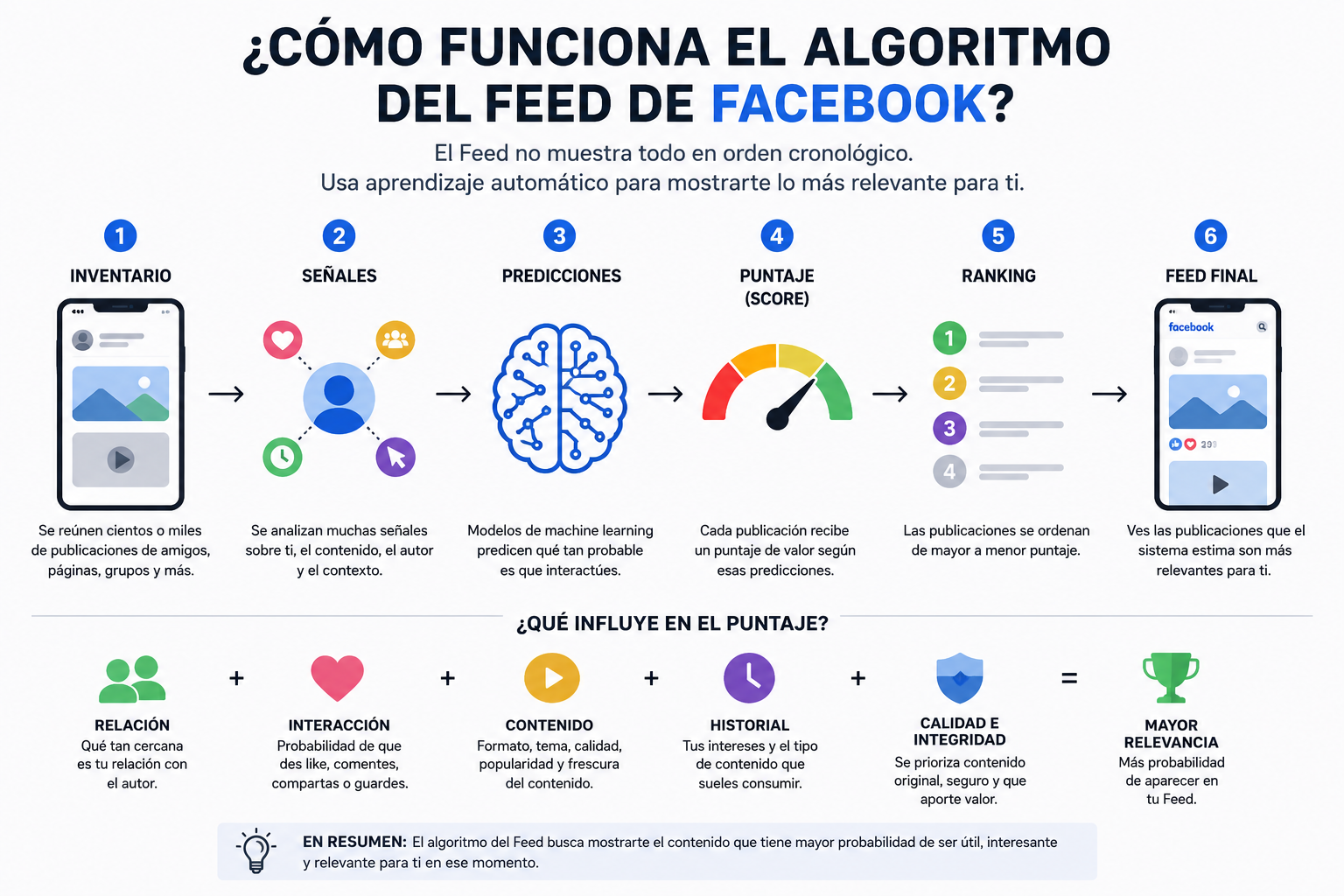
Este sistema está basado en machine learning y funciona con miles de señales relacionadas con el usuario, el contenido, el autor de la publicación y el contexto en el que la persona abre la aplicación.
Para entenderlo mejor, vamos a explicarlo de forma sencilla, pero con una capa técnica: veremos qué son las señales, cómo se calculan las probabilidades, qué significa el score de una publicación y cómo se puede representar el ranking del Feed con ecuaciones.
La idea central es esta:
¿Qué problema intenta resolver el algoritmo del Feed?
Facebook tiene un problema enorme: cada usuario puede tener cientos o miles de publicaciones potenciales para ver. Estas publicaciones pueden venir de amigos, páginas, grupos, videos, enlaces, fotos, conversaciones activas o contenido que el usuario no alcanzó a ver en sesiones anteriores.
Si Facebook mostrara todo en orden cronológico, el usuario podría perderse contenido importante de personas cercanas, ver demasiadas publicaciones repetitivas o recibir contenido que no le interesa.
Por eso existe el ranking.
El ranking intenta responder esta pregunta:
¿Qué publicación tiene mayor probabilidad de generar valor para este usuario?
Ese valor puede venir de distintas acciones:
Pero también puede haber señales negativas:
Nota: Por eso el algoritmo no se reduce a “más likes = más alcance”. El sistema intenta calcular una estimación más completa del valor esperado de cada publicación.
Conceptos básicos para entender el ranking
Antes de entrar a ecuaciones, necesitamos definir algunos conceptos.
1. Usuario
Es la persona que abre Facebook.
En notación matemática podemos representarlo como:
Publicación candidata
Es cada post que podría aparecer en el Feed del usuario.
Tiempo o contexto de sesión
El ranking no ocurre en el vacío. El momento importa: cuándo abre la app, qué acaba de hacer, qué publicaciones son recientes y qué contenido está activo.
Señales o features
Las señales son datos que el modelo usa para hacer predicciones.
Ejemplos de señales:
Predicción
El modelo intenta predecir si el usuario hará cierta acción.
Por ejemplo:
Valor final o score
Después de calcular varias predicciones, el sistema necesita combinarlas en una puntuación final.
Ese valor final ayuda a ordenar el Feed.
La primera fórmula: representar una publicación con señales
Una publicación no se evalúa solamente por su texto, imagen o número de likes. Se evalúa como un conjunto de características.
Podemos representarla así:
Donde:
Ejemplo aplicado:
Nota: Agrega aqui el insight clave.En marketing digital, esto es importante porque cada publicación genera señales. No compites solamente con creatividad; compites con datos de comportamiento.
Predicción básica de una acción
El sistema puede usar las señales para predecir una acción.
La forma general sería:
Esto significa:
Por ejemplo, para predecir si el usuario dará like:
Esto se lee así:
Para predecir comentario:
Para predecir compartido:
Para predecir visualización:
Para predecir rechazo:
Aquí empezamos a ver algo importante: el algoritmo no piensa en una sola métrica. Piensa en muchas probabilidades al mismo tiempo.
Ejemplo con regresión logística
Una forma clásica de convertir señales en probabilidad es usar una función sigmoide, común en modelos de clasificación.
Donde:
En palabras simples:
Nota: El modelo toma muchas señales, les asigna pesos, las combina y las transforma en una probabilidad entre 0 y 1.
Ejemplo:
Eso significa:
No quiere decir que el usuario definitivamente comentará. Significa que, con base en señales históricas y contextuales, la probabilidad estimada es alta.
El Feed usa múltiples objetivos
Un error común es pensar que Facebook solo busca maximizar likes.
En realidad, el sistema puede considerar múltiples objetivos:
Cada objetivo representa una predicción diferente.
Por ejemplo:
Esta publicación quizá no tiene altísima probabilidad de comentario, pero tiene alta probabilidad de reproducción. Entonces puede ser relevante para un usuario que consume mucho video.
Otra publicación podría tener bajo nivel de likes, pero alta probabilidad de generar conversación significativa. Para ciertos usuarios, esa publicación puede tener más valor que un post visualmente atractivo pero superficial.
Función de valor del contenido
Después de calcular varias predicciones, el sistema necesita convertirlas en una sola puntuación.
Una forma simplificada de representar esto es:
Donde:
En versión más general:
Esto se lee así:
Donde:
Esta fórmula es clave para entender el ranking: no se trata de una métrica aislada, sino de una combinación de probabilidades.
Ejemplo numérico
Supongamos que Facebook evalúa una publicación para un usuario específico.
Predicciones:
Pesos hipotéticos:
Cálculo:
Resultado:
Ese 2.65 sería una puntuación estimada de valor para esa publicación.
Si hay varias publicaciones candidatas, cada una recibe su propio score.
Ranking inicial:
Pero ese no siempre es el resultado final. Después pueden aplicarse reglas adicionales de diversidad, integridad, frescura y contexto.
Inventario: el primer paso del ranking
Antes de calcular scores, el sistema necesita reunir publicaciones candidatas.
A esto le podemos llamar inventario.
El inventario puede incluir:
En pseudocódigo:
La idea es sencilla:
Scoring: calcular la puntuación de cada publicación
Una vez reunido el inventario, el sistema calcula señales y predicciones.
Después se calculan predicciones:
Y luego se calcula el score:
Algoritmo completo del Feed
Una versión didáctica del ranking sería:
En Python simplificado:
*Este código no es el sistema real de Facebook, pero representa la lógica conceptual del ranking: inventario, señales, predicciones, score, ordenamiento y ajustes finales.
**Este artículo está basado en la explicación técnica de Meta, donde describen el ranking del Feed con inventario de publicaciones, predicciones Y_ijt, valor final V_ijt, modelos multitarea, embeddings, feed aggregator, ranking en pases y una combinación lineal de predicciones para el score final.
0 comentarios
Todavia no hay comentarios publicados
Se el primero en dejar una opinion y calificacion.